Temporally Extended Mixture-of-Experts Models
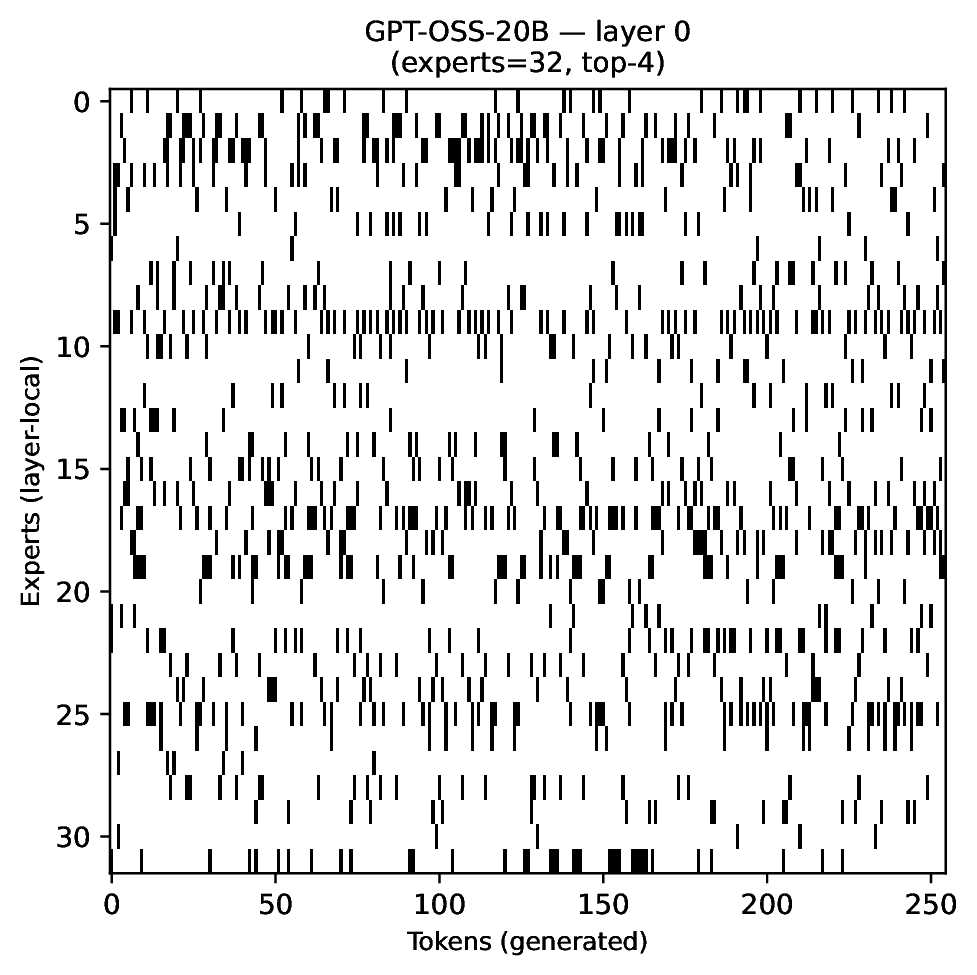
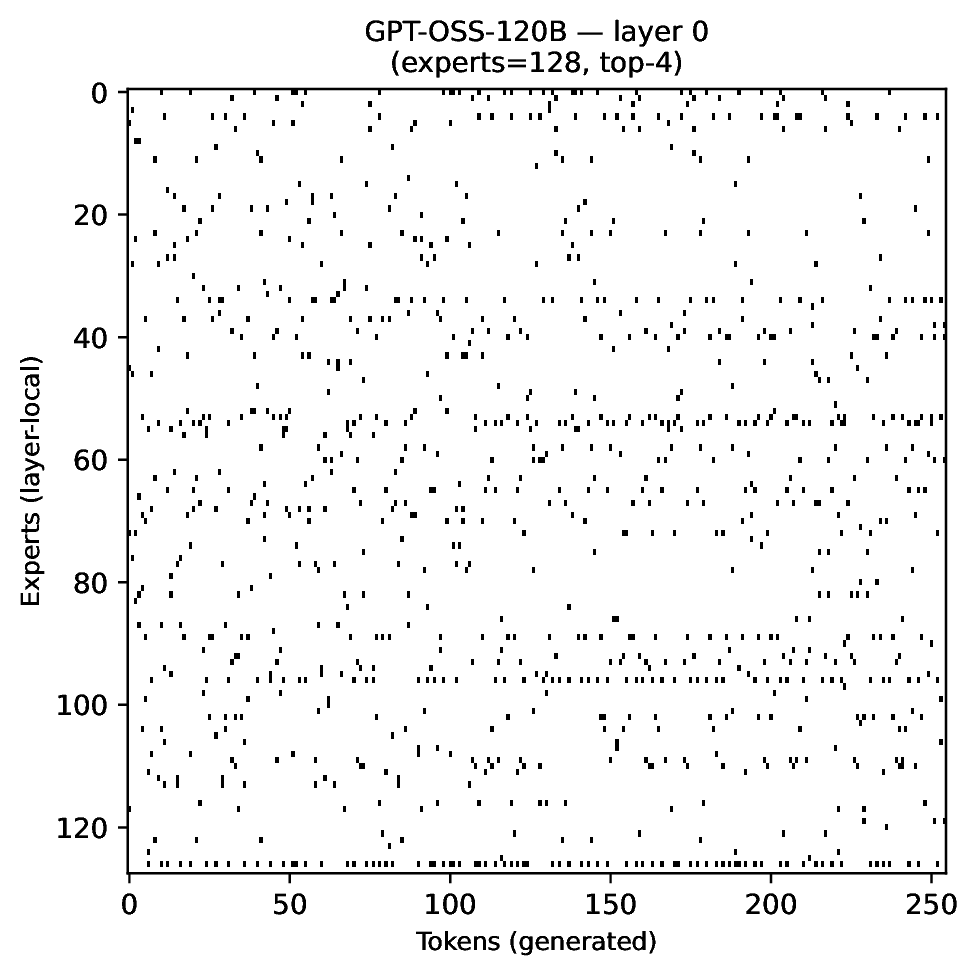
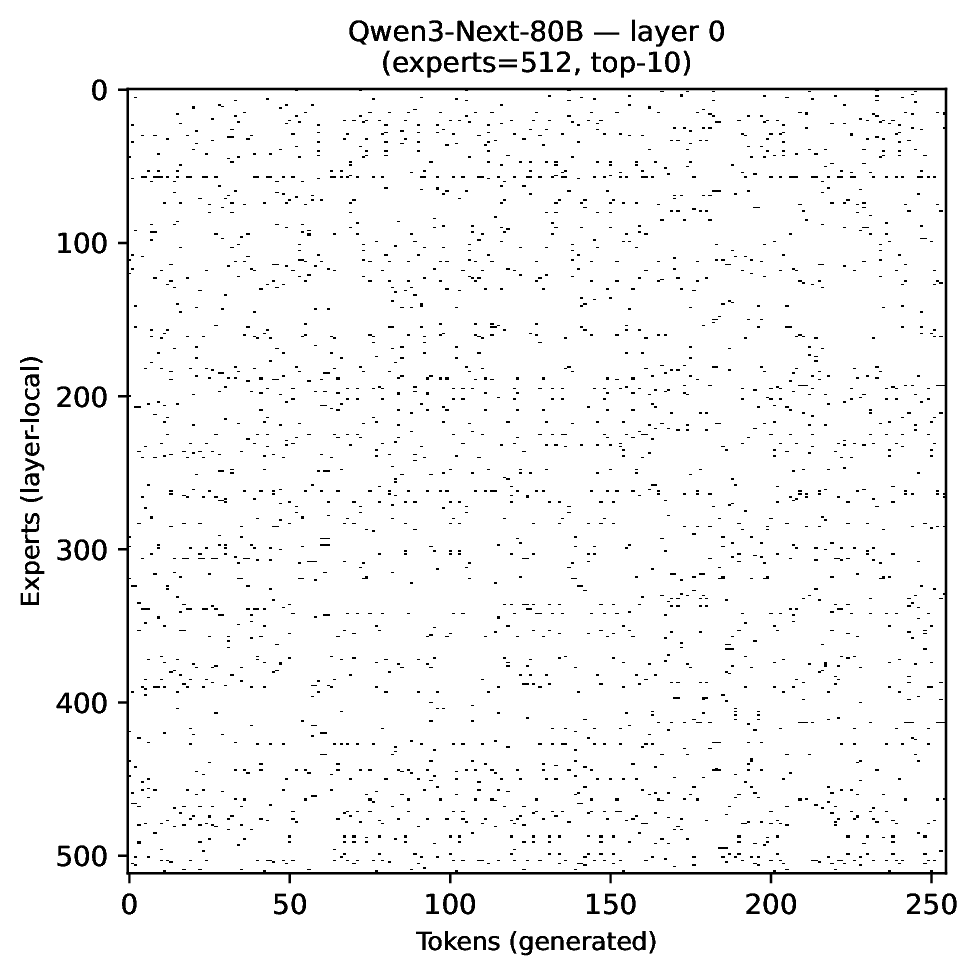
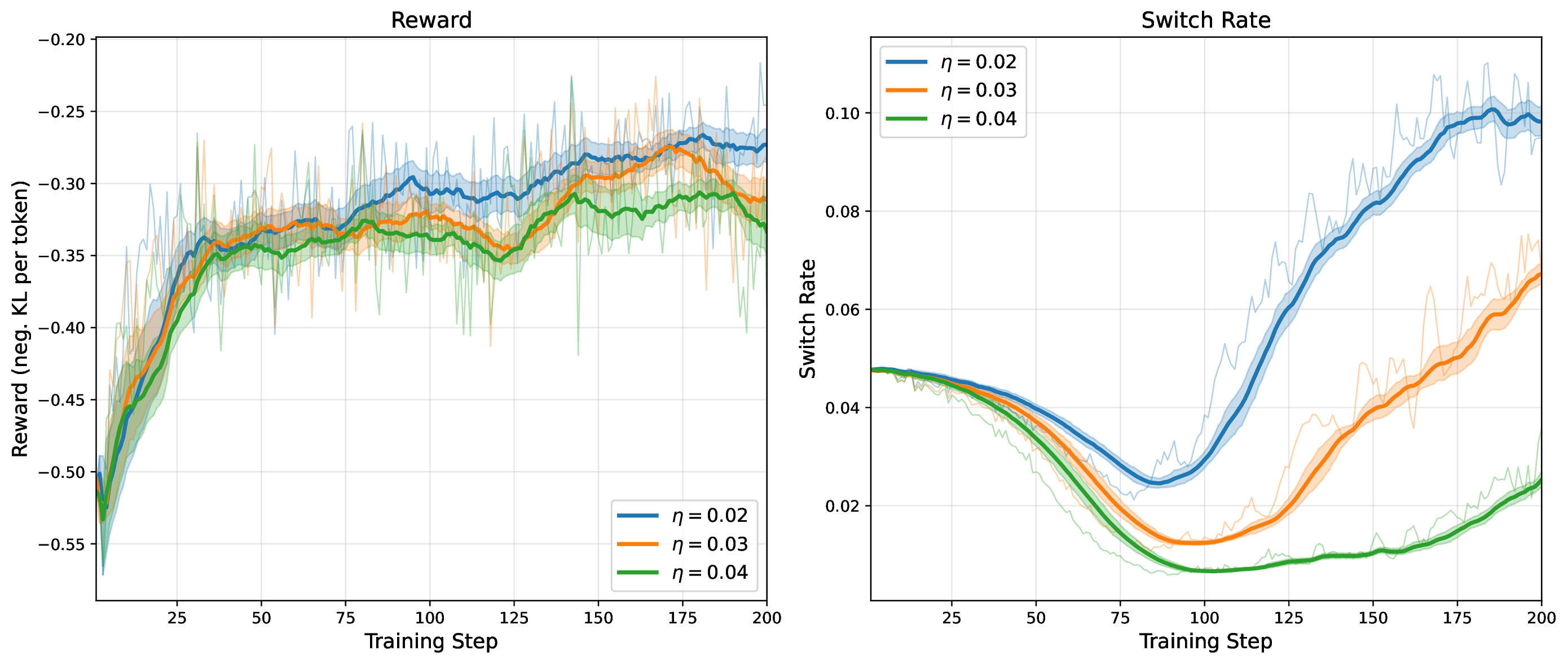
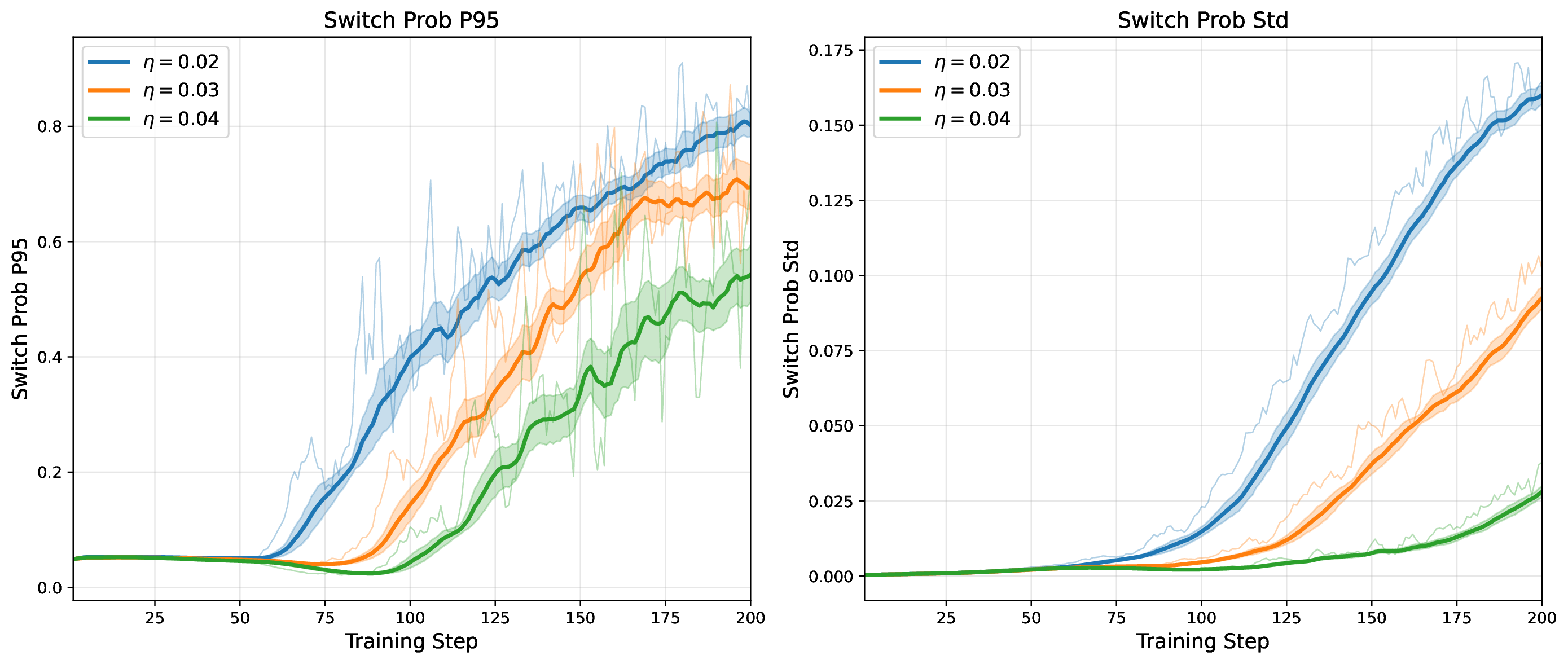
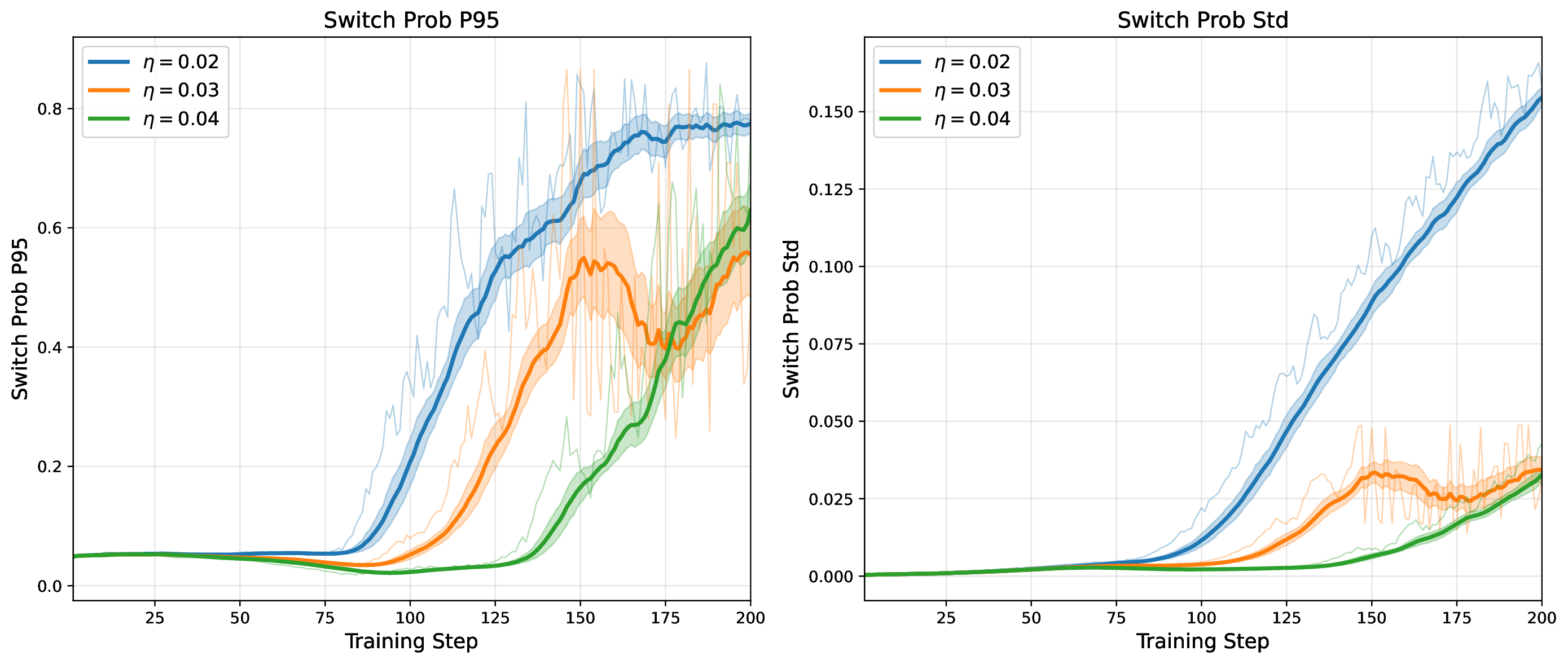
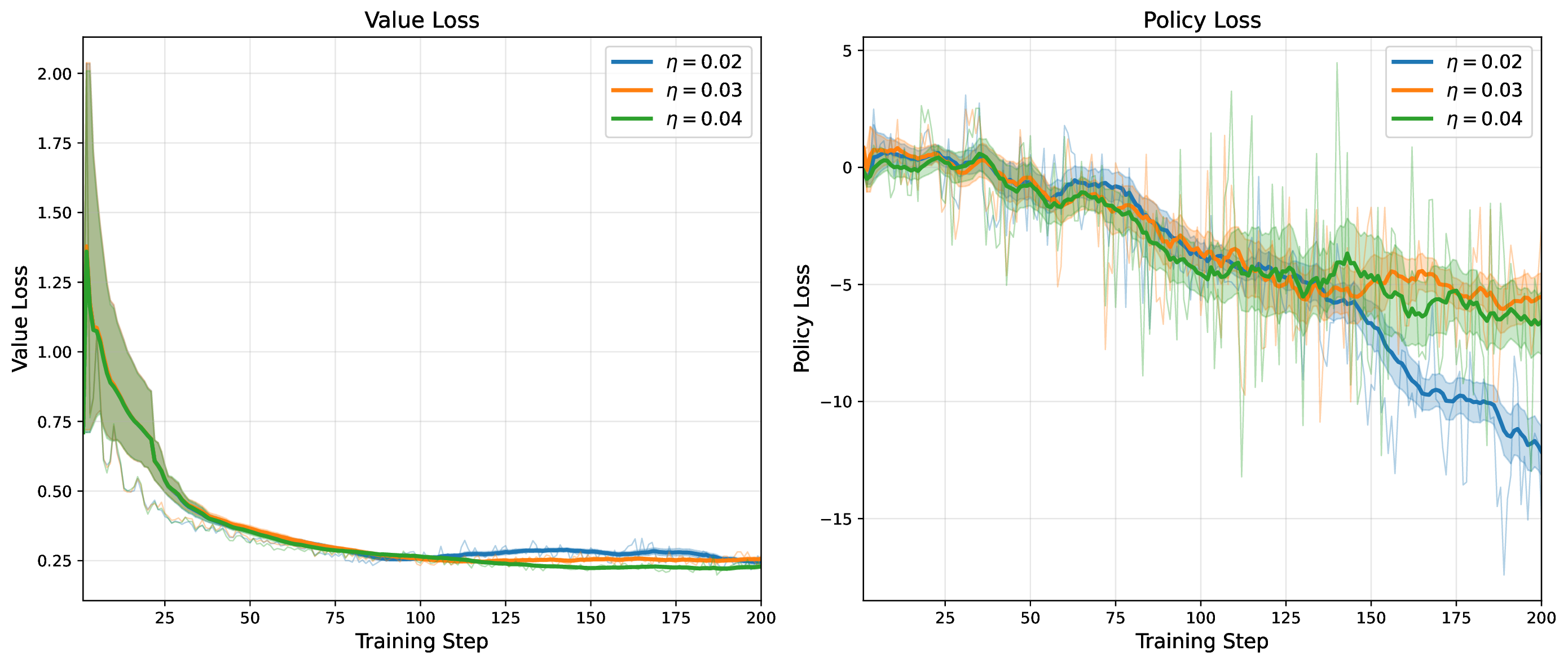
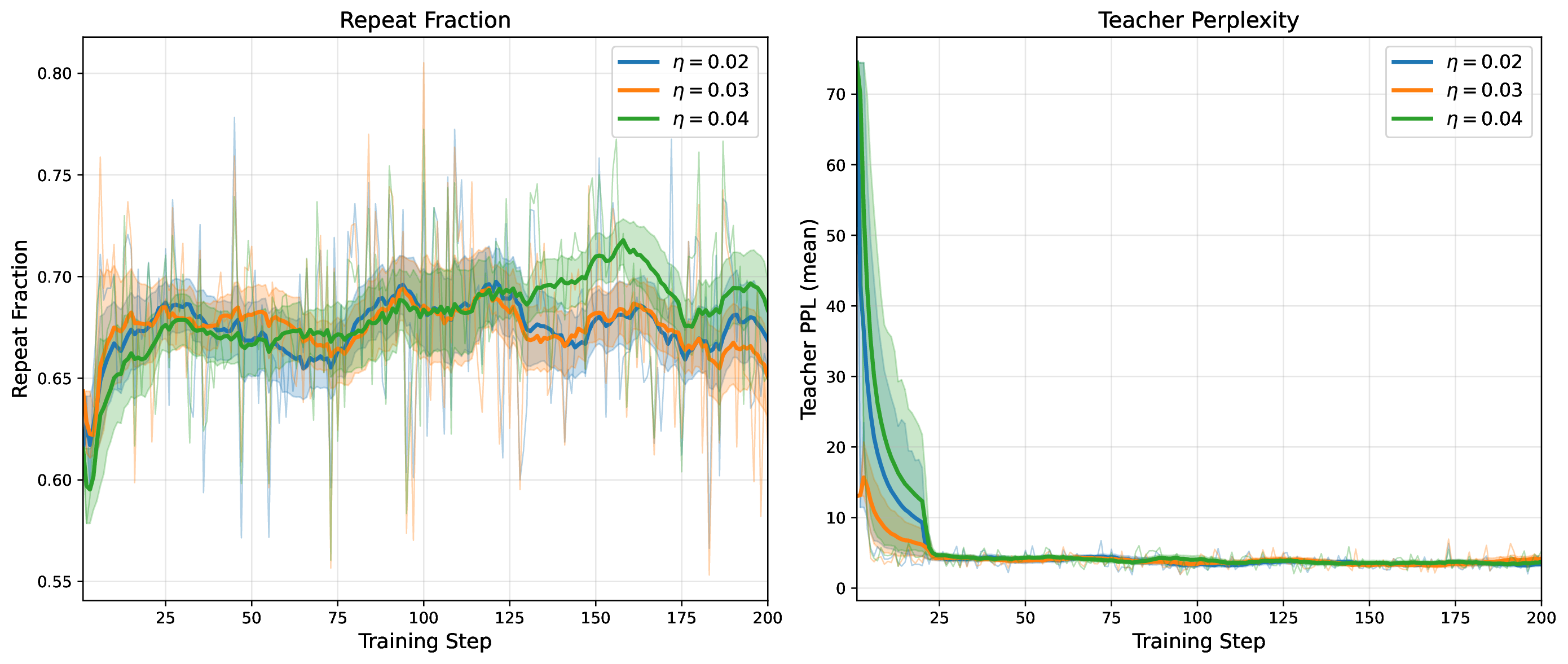
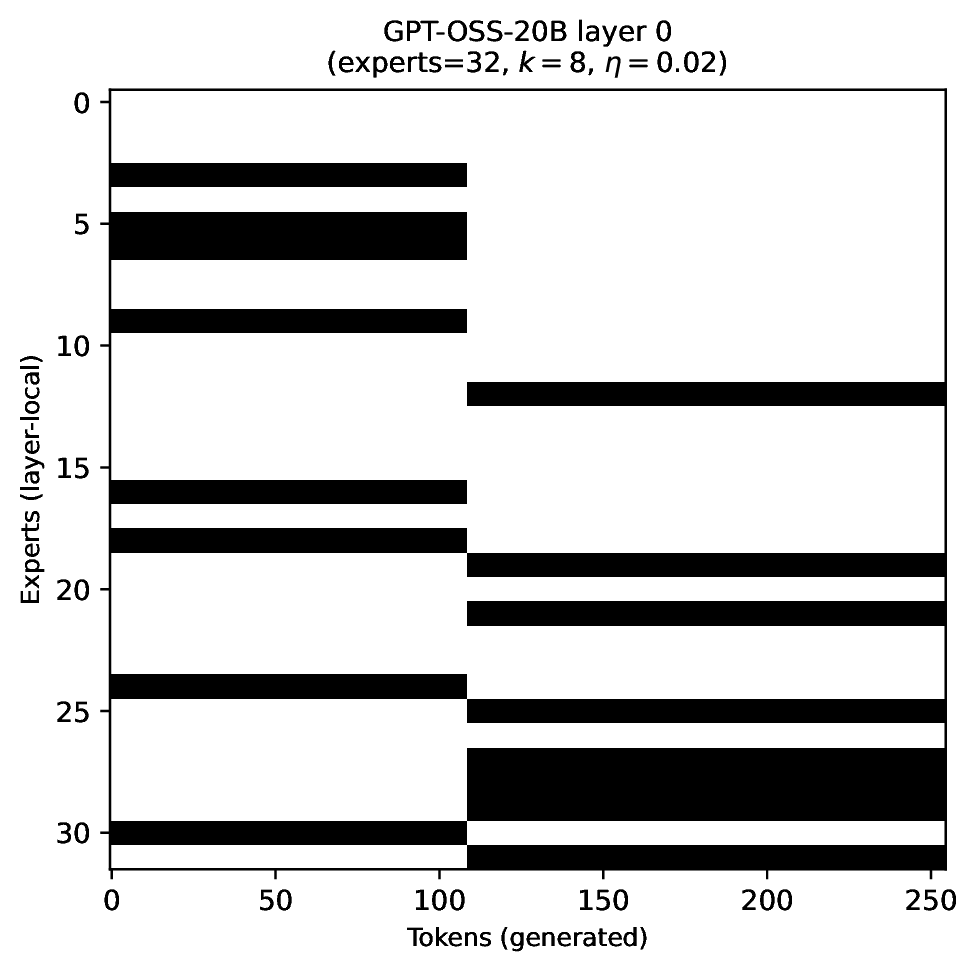
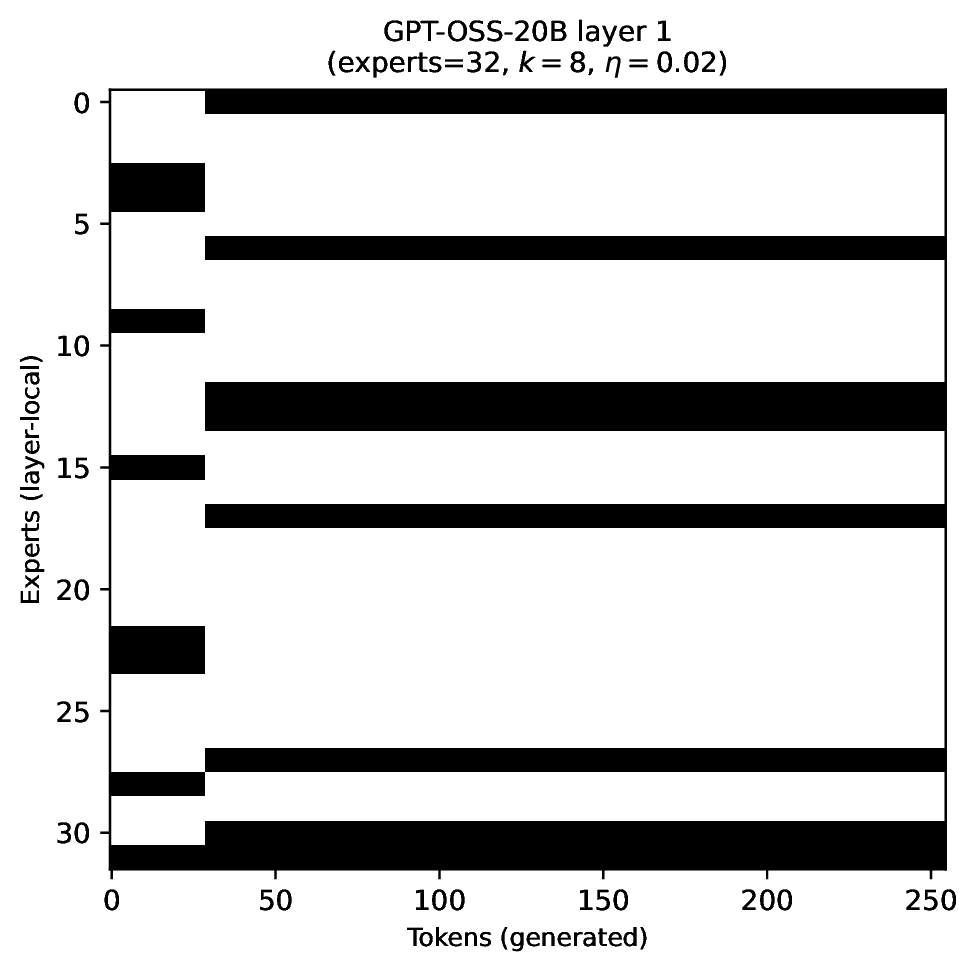
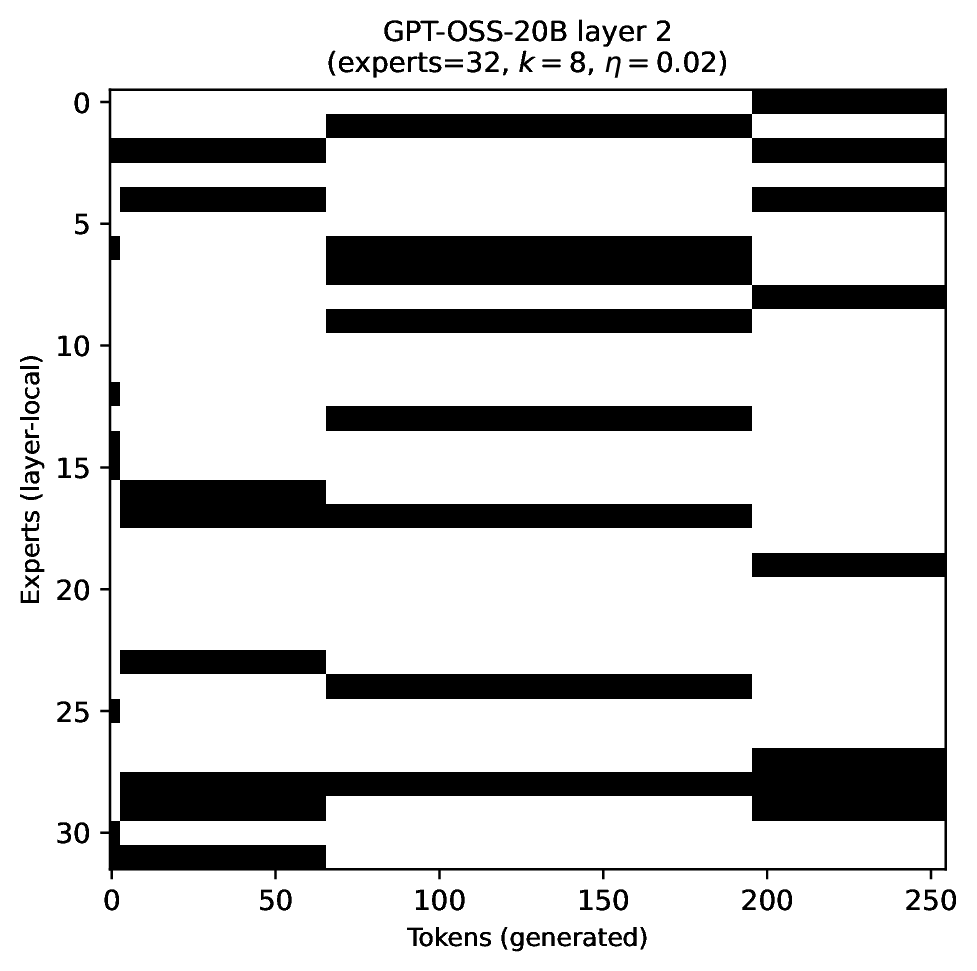
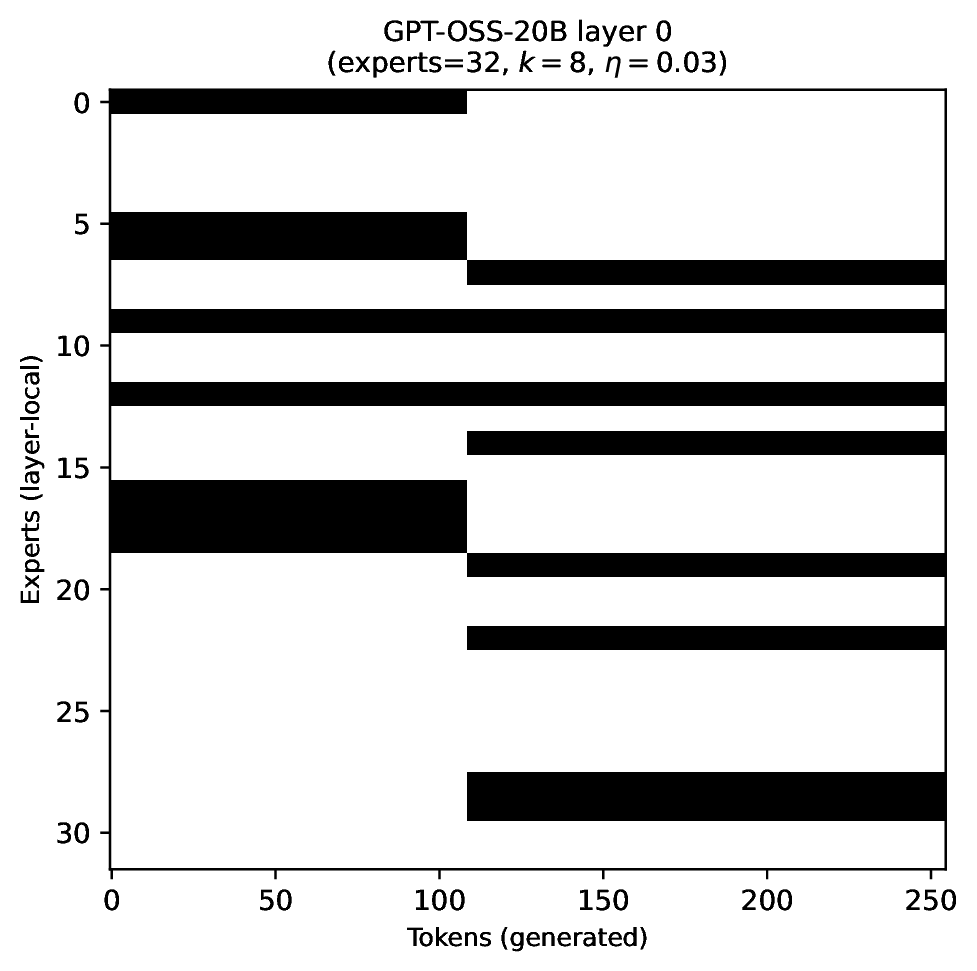
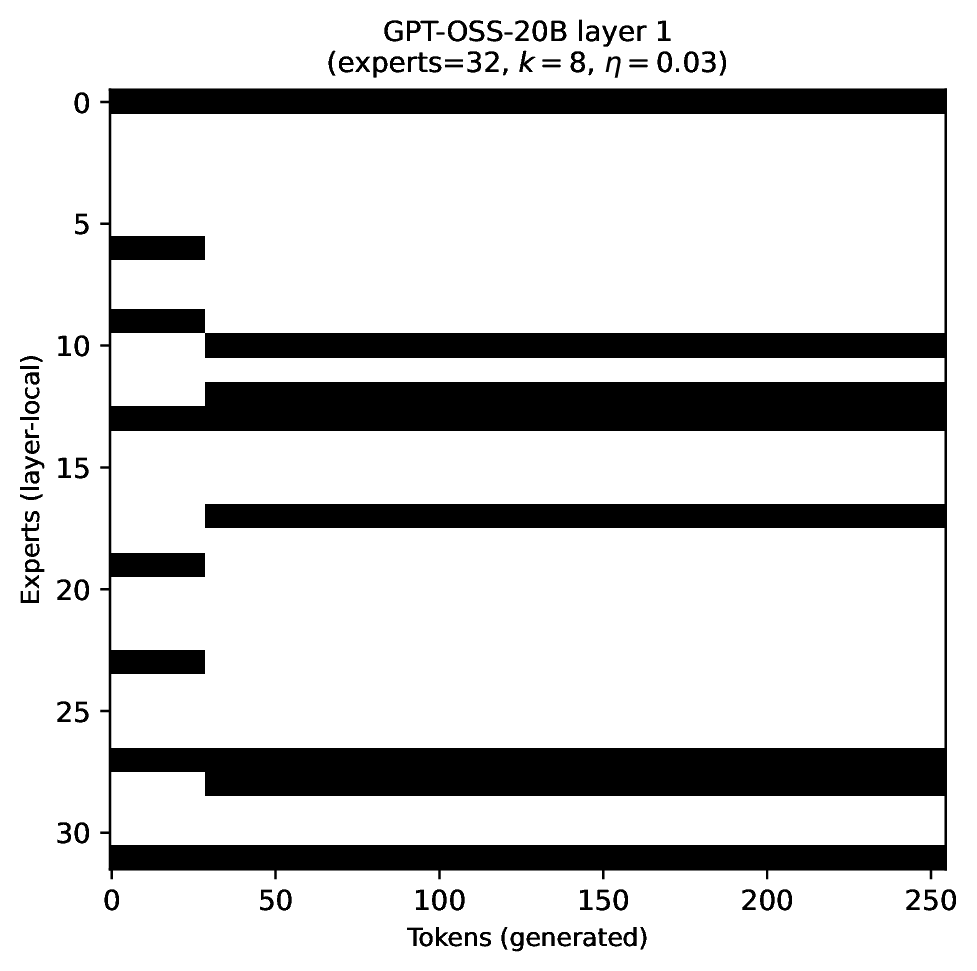
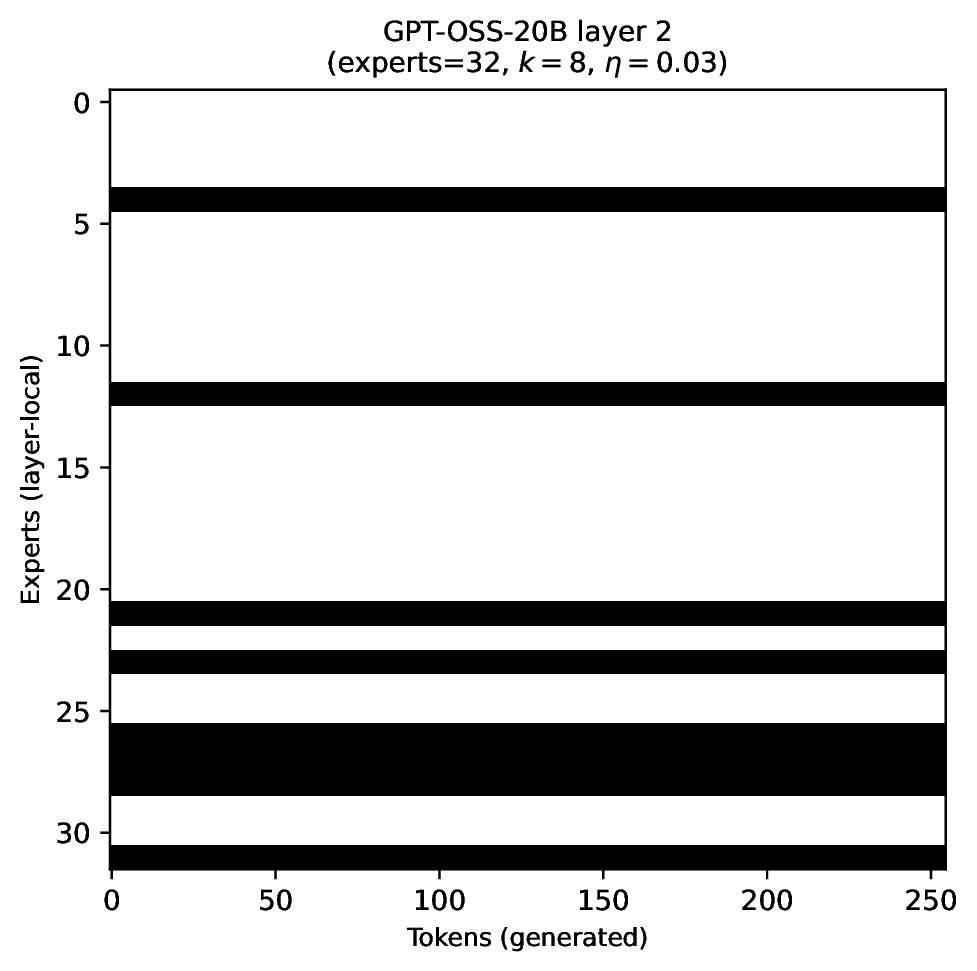
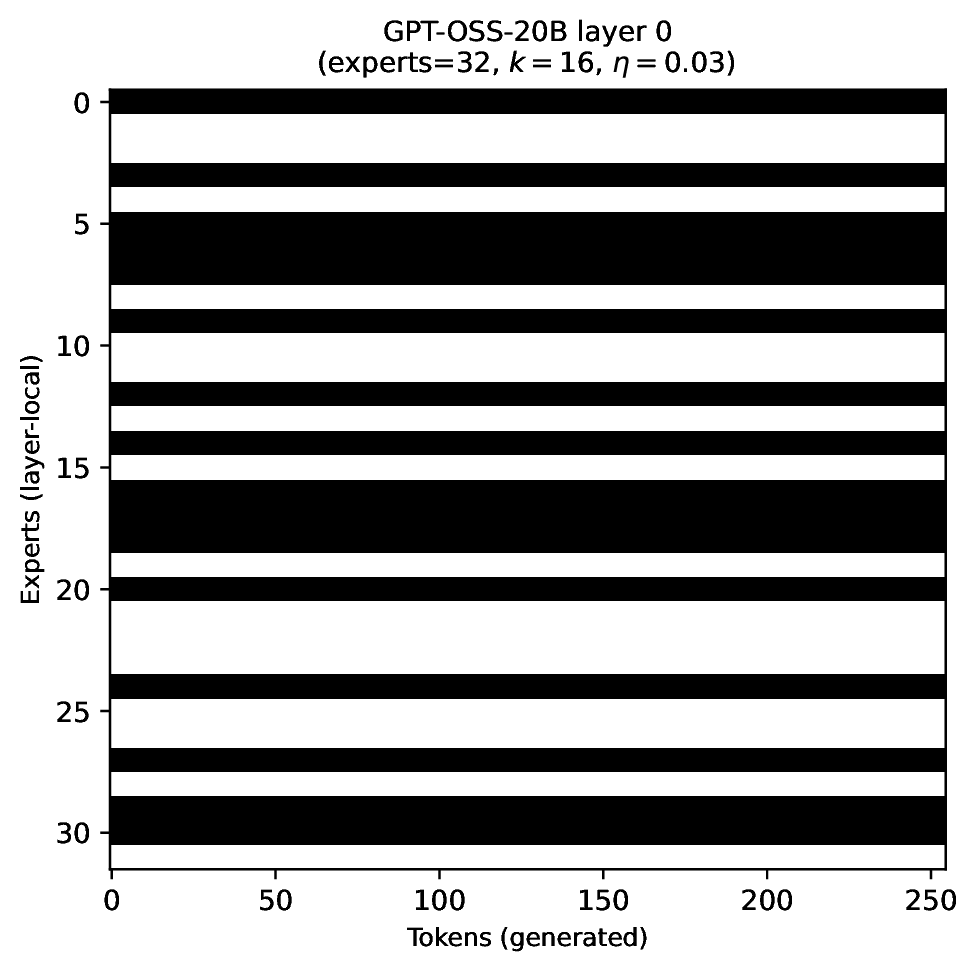
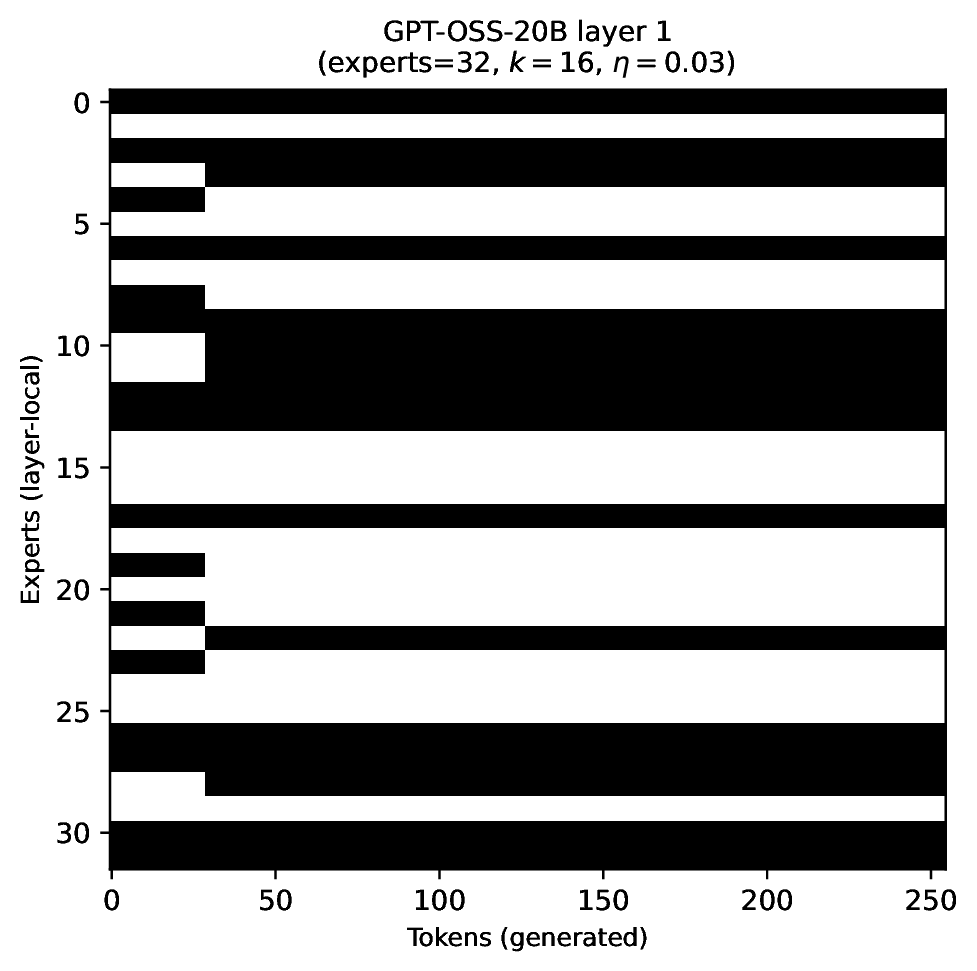
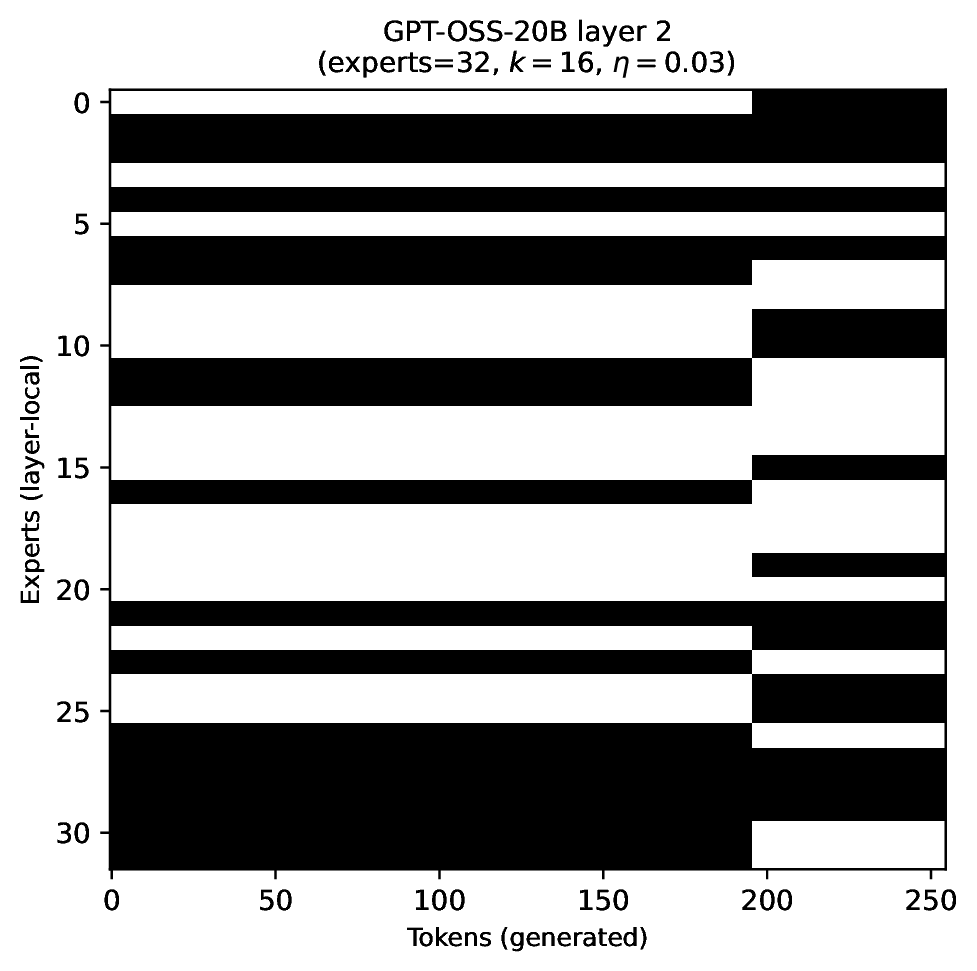
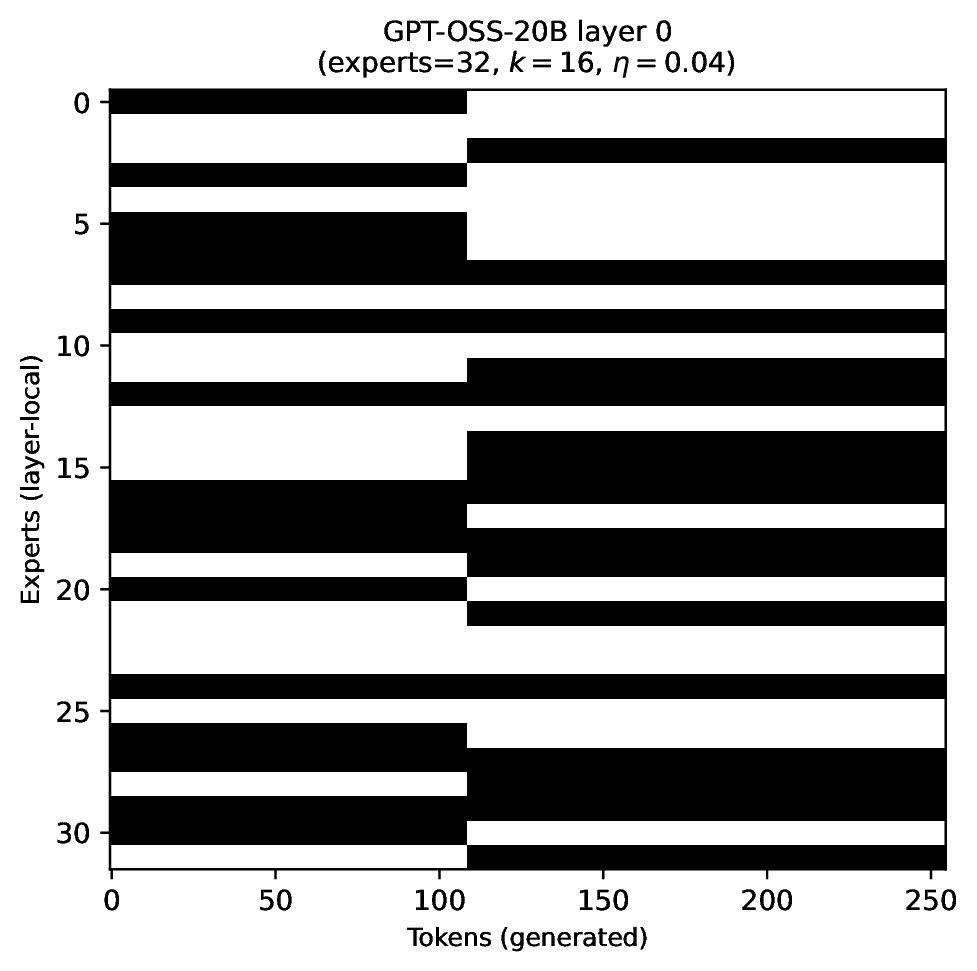
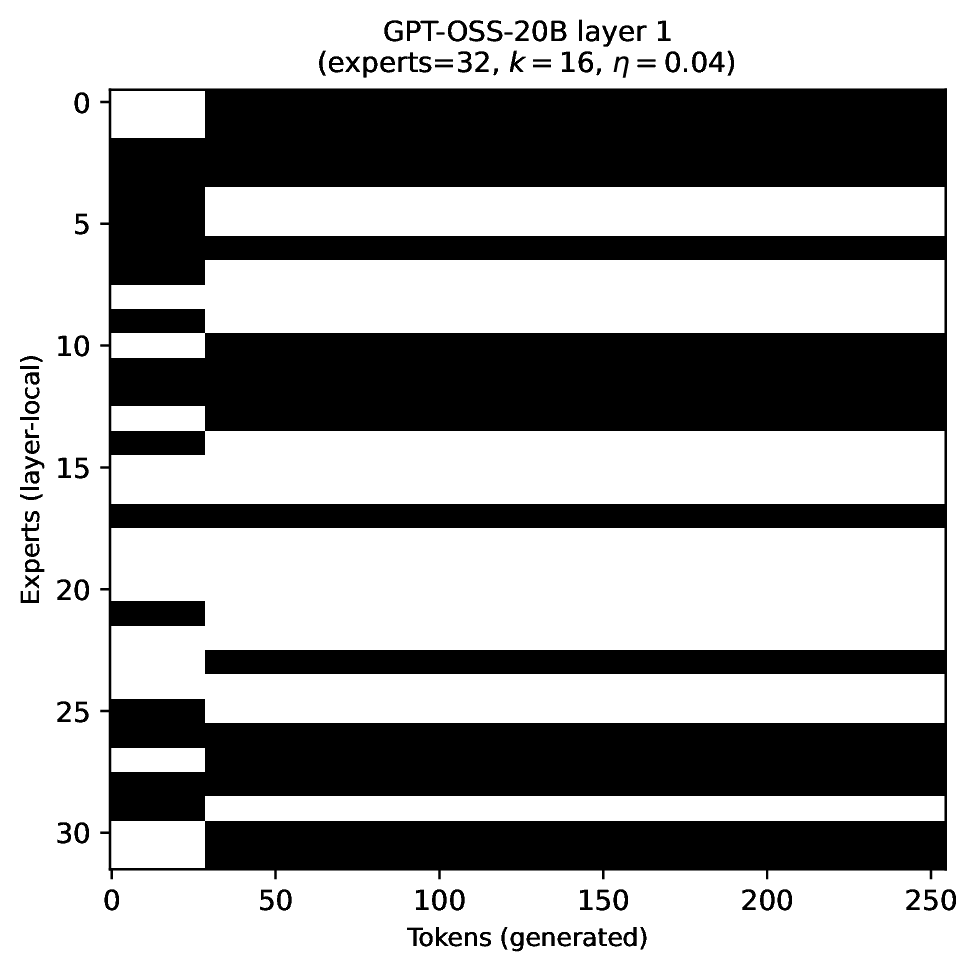
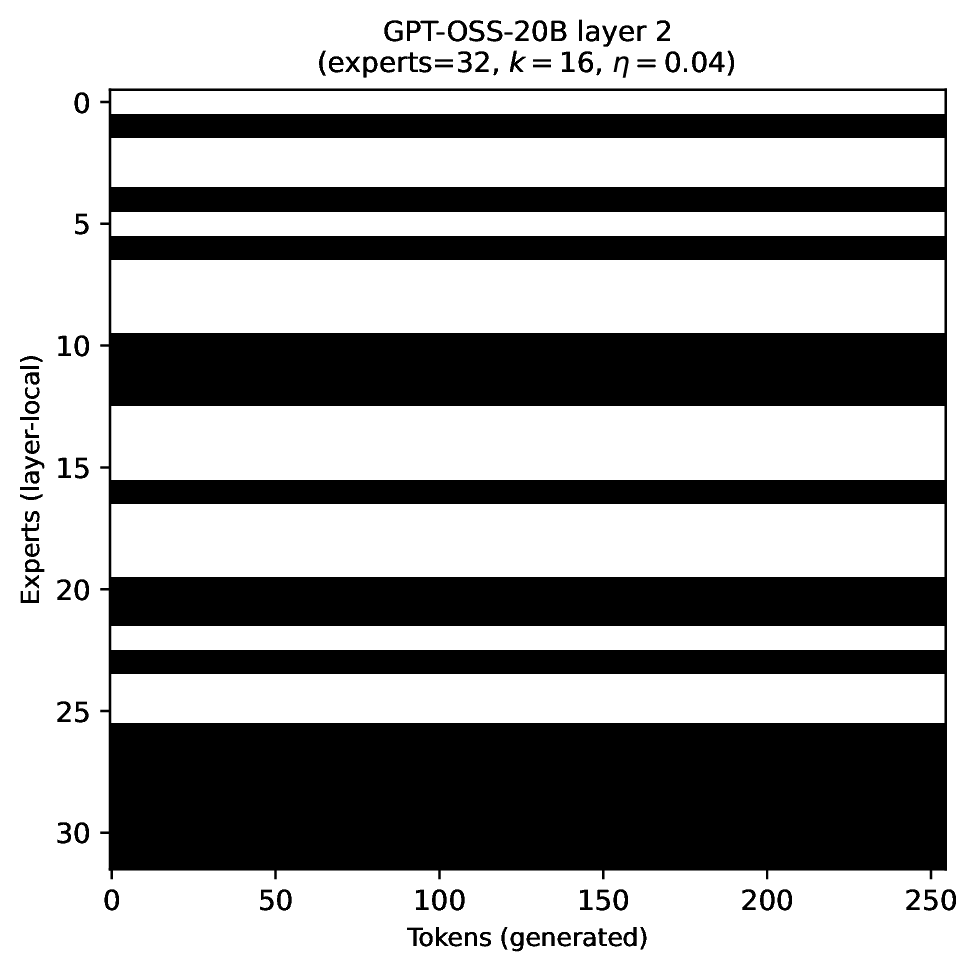
Modern MoE LLMs switch their active expert set at almost every generated token. That foreclosures memory optimizations like offloading once expert counts outgrow GPU capacity. We argue that this is exactly the structure that options with deliberation costs were designed for — and show that even pretrained MoEs (like gpt-oss-20b) can be cheaply converted into temporally extended ones, dropping switch rates from >50% to under 5% while retaining most of the base model's accuracy.
Princeton University
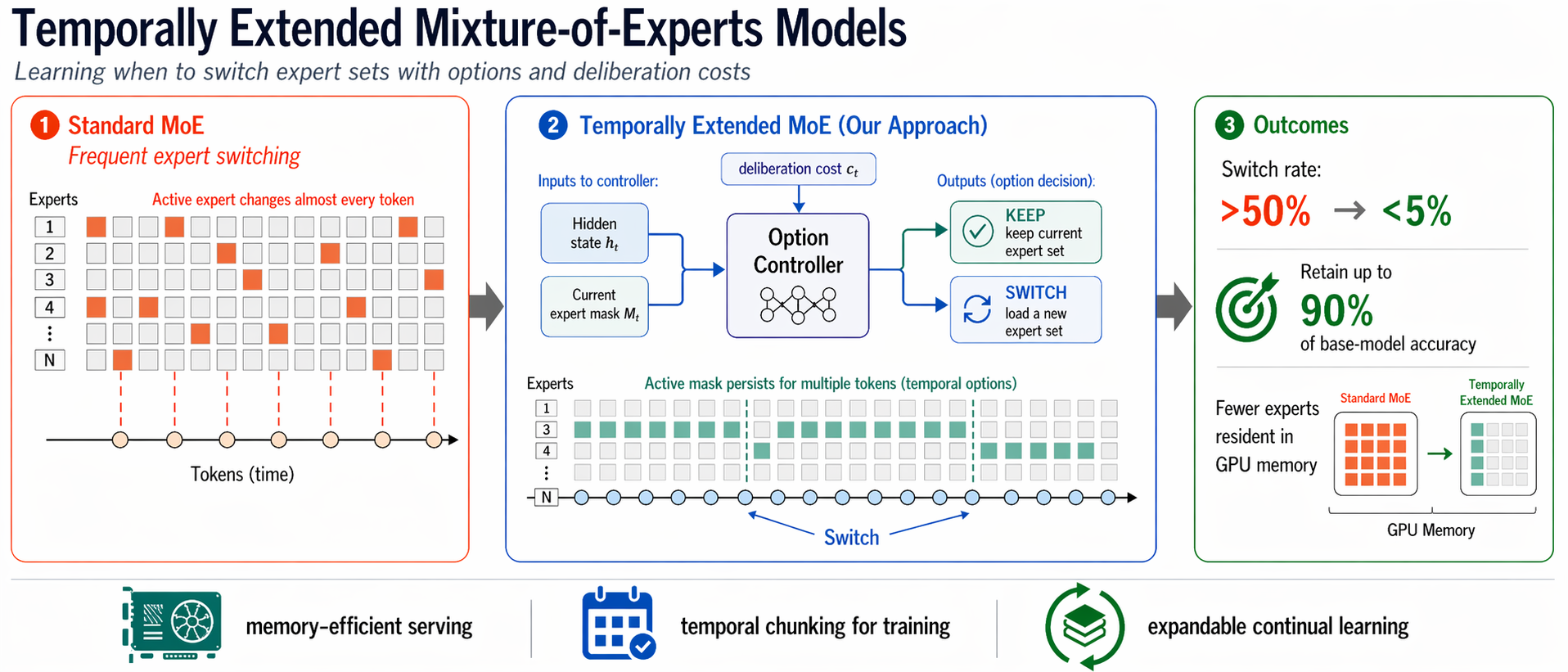
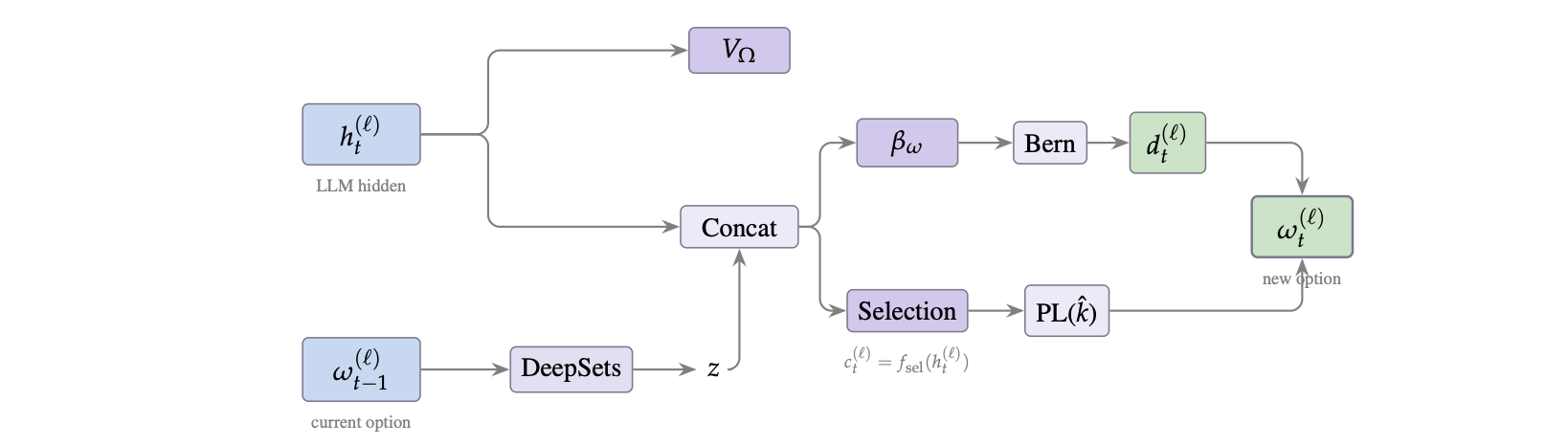
Standard MoEs change their active expert set at almost every token. Our option controller learns when to keep the current set and when to switch, governed by a deliberation cost η. The result: switch rates collapse from over 50% to below 5%, while accuracy stays close to the base model — opening the door to memory-efficient serving, temporal chunking for training, and continual expansion of the expert pool.