Key Results
- Top simulators achieve higher preference win rates compared to questions asked by actual justices. Humans preferred simulated questions, which were overall more competitive than actual questions, to justices’ real questions. This is partially because simulated questions always addressed some argument, while actual justice remarks were sometimes targeted at courtroom logistics or procedural details.
See human evaluation results
Pairwise preference judgments from law students and researchers. Models above the line outperform ground truth.
Model Wins Losses Ties Win Rate Gemini-2.5-Pro (Agent) 72 31 25 55.6% Llama-3.3-70B (Prompt) 66 37 34 54.6% GPT-4o (Prompt) 62 46 31 51.0% Gemini-2.5-Pro (Prompt) 62 41 26 49.3% Ground Truth 46 55 33 41.1% GPT-4o (Agent) 45 52 32 40.1% Qwen3-32B (Prompt) 42 58 24 35.5% gpt-oss-120b (Prompt) 36 60 28 32.9% gpt-oss-120b (Agent) 24 75 17 21.4% Win rates are weighted (ties = 0.5). 152 total matches from law students and graduate researchers in a blind arena evaluation.
- Models cover most legal issues broadly but miss specific subcomponents. 5 of 8 simulators address over 60% of ground truth issues when we ask if a simulated question addresses any aspect of a legal issue. When we ask if a simulated question addresses all aspects of an issue, the best model covers only 41% of raised issues.
See issue coverage results
ISSUE-BROAD: any aspect addressed. ISSUE-NARROW: all subcomponents covered. Evaluated on 30 transcript sections.
Model Broad Narrow gpt-oss-120b (Default) 64.1% 41.3% Gemini-2.5-Pro (Default) 63.7% 25.0% Qwen3-32B (Default) 62.2% 30.2% Llama-3.3-70B (Default) 62.1% 22.6% Gemini-2.5-Pro (Agent) 62.0% 26.3% gpt-oss-120b (Agent) 59.4% 32.1% GPT-4o (Agent) 56.4% 23.7% GPT-4o (Default) 54.7% 20.8% Agentic simulators with docket search tools tend to achieve higher issue coverage than prompt-only variants.
Explore per-case issue coverage
For each case, we extract the substantive legal issues from the full transcript, then check whether each simulator's questions address them.
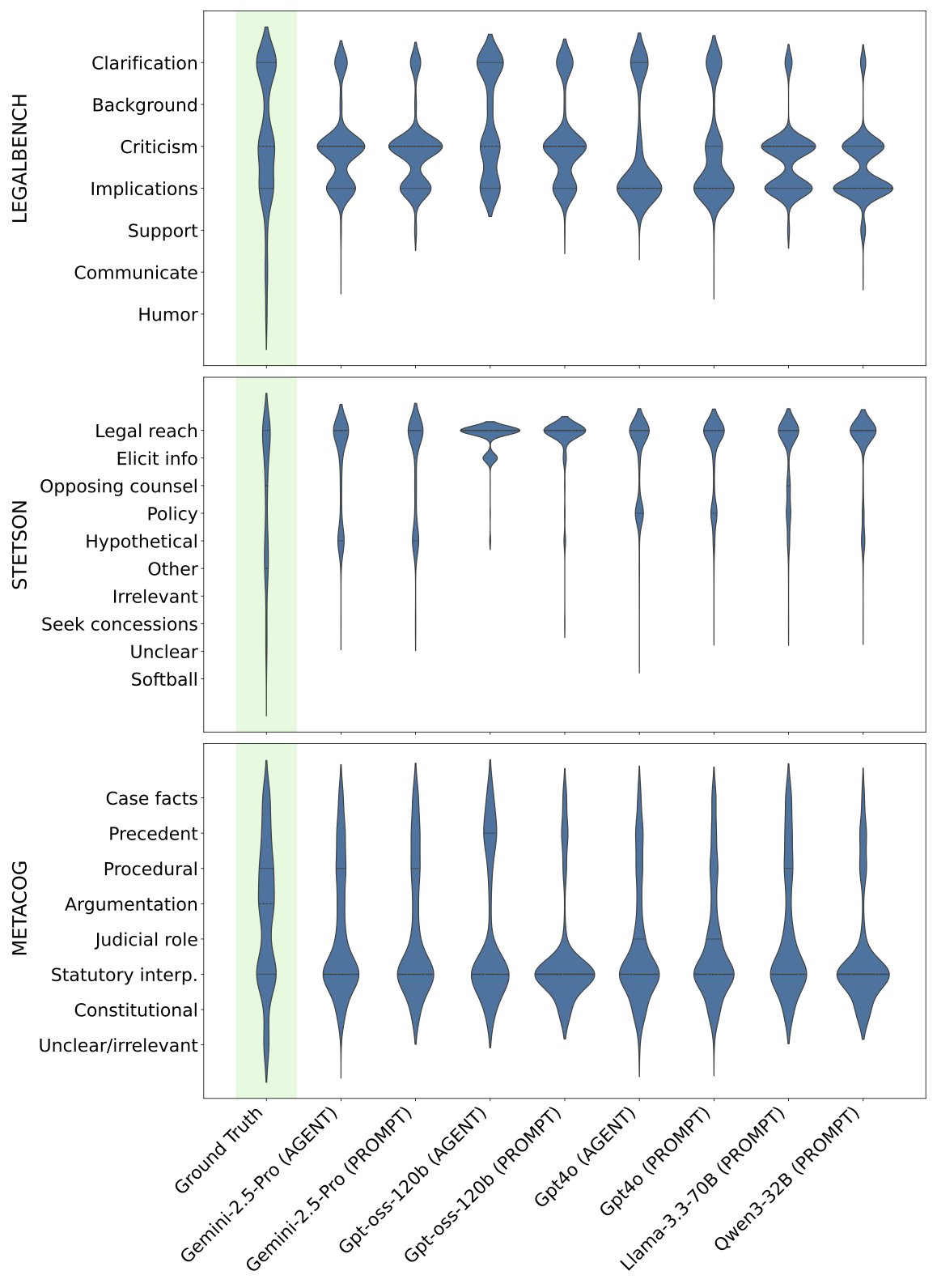
- The diversity of generated question types is a major weakness. Simulated question distributions concentrate on 1–2 questions across each metric, while real question distributions spread across many categories.
See question diversity results
Jensen-Shannon Divergence from ground truth distribution (lower = more diverse, closer to real justices):
Model LegalBench Stetson MetaCog Llama-3.3-70B (Default) 0.122 0.134 0.080 Qwen3-32B (Default) 0.131 0.153 0.149 Gemini-2.5-Pro (Agent) 0.072 0.095 0.059 Gemini-2.5-Pro (Default) 0.087 0.109 0.072 gpt-oss-120b (Agent) 0.036 0.189 0.129 gpt-oss-120b (Default) 0.061 0.171 0.180 GPT-4o (Agent) 0.124 0.179 0.084 GPT-4o (Default) 0.069 0.140 0.089 No single model dominates across all taxonomies. The three classification schemes assess question types from different legal perspectives.
Here, we plot the distributions shapes and show the different classification categories:
- Models are sycophantic, a common pitfall for education contexts, but especially for adversarial pedagogical contexts like oral arguments. While this is a common pitfall in educational contexts, this seems especially adversarial in moot court simulations where the task is to adversarially assess the argument, like a court would do. In adversarial tests, simulators push back against less than 40% of decorum violations and less than 10% of rage-bait or switching-sides provocations. Real justices would immediately challenge these (and likely even eject the attorney depending on the severity of the transgression).
See adversarial test results
Three test types, 50 samples each. A real justice would push back on virtually all of these violations.
Model Decorum Rage Bait Switching Sides Gemini-2.5-Pro 36.0% 6.0% 0.7% Llama-3.3-70B 30.0% 0.7% 0.7% Gemini-2.5-Pro (Agent) 28.0% 8.0% 6.0% GPT-4o 8.7% 0.7% 0.0% Qwen3-32B 4.0% 0.0% 0.0% gpt-oss-120b 2.7% 0.0% 0.0% gpt-oss-120b (Agent) 0.0% 0.0% 0.0% GPT-4o (Agent) 0.0% 0.0% 0.0% Over-alignment causes models to accept provocative or absurd behavior. This is the most significant gap between simulated and real oral arguments.
Real justices would immediately challenge these. Hear Justice Gorsuch admonishing an attorney.
In A.J.T. v. Osseo Area Schools (April 2025), advocate Lisa Blatt accused opposing counsel of “lying.” Justice Gorsuch immediately pushed back — and spent several minutes reading from Blatt's own briefs to force a retraction. No current AI simulator would do this.
- Fallacy detection is strong for most types. Best models catch over 80% of fallacies in 7 of 10 categories. However, all struggle with numerical reasoning (Numbers, Sampling), consistent with known LLM limitations.
See fallacy detection results
10 fallacy types embedded in advocate responses. The MOOT_COURT prompt consistently improves detection.
Fallacy Type Best Model Caught Sufficient vs. Necessary Llama / Qwen / Gemini / gpt-oss-120b Agent 100.0% Exclusivity Flaw Qwen3-32B 100.0% Factual — Legal Qwen3-32B / gpt-oss-120b 100.0% Ignoring Justice Llama-3.3-70B 100.0% Comparison Fallacy Llama-3.3-70B / Gemini Agent 87.5% Factual — General Gemini-2.5-Pro 87.5% Misstating Justice Llama-3.3-70B / Gemini Agent / gpt-oss-120b 87.5% Correlation vs. Causation Gemini-2.5-Pro / Gemini Agent 75.0% Sampling Flaw Gemini-2.5-Pro 75.0% Numbers Flaw Gemini-2.5-Pro 50.0% The MOOT_COURT prompt, which explicitly instructs models to nitpick logical errors, yields consistent improvement across all base models.