The Problem
Legal citations play a prominent role in U.S. legal practice. Attorneys must point to past judicial decisions and laws to make their case. Fabricating citations, or misrepresenting the content of those citations, is the same as pointing to made-up law to win the case — one judge called it:
"an abuse of the adversary system" that puts the integrity of the judicial process at risk. — Noland v. Land of the Free, 114 Cal.App.5th 426, 445 (2025)
The rapid adoption of large language models (LLMs) in the legal system has turned rare individual instances of fabrication into a systemic problem. Pro se litigants, trained attorneys, and even judges are using LLMs to generate briefs, motions, and other court filings. A prevailing argument has been that this problem is temporary — that hallucination rates would diminish as models improve and that high-profile sanctions would induce greater caution. Our findings challenge these assumptions.
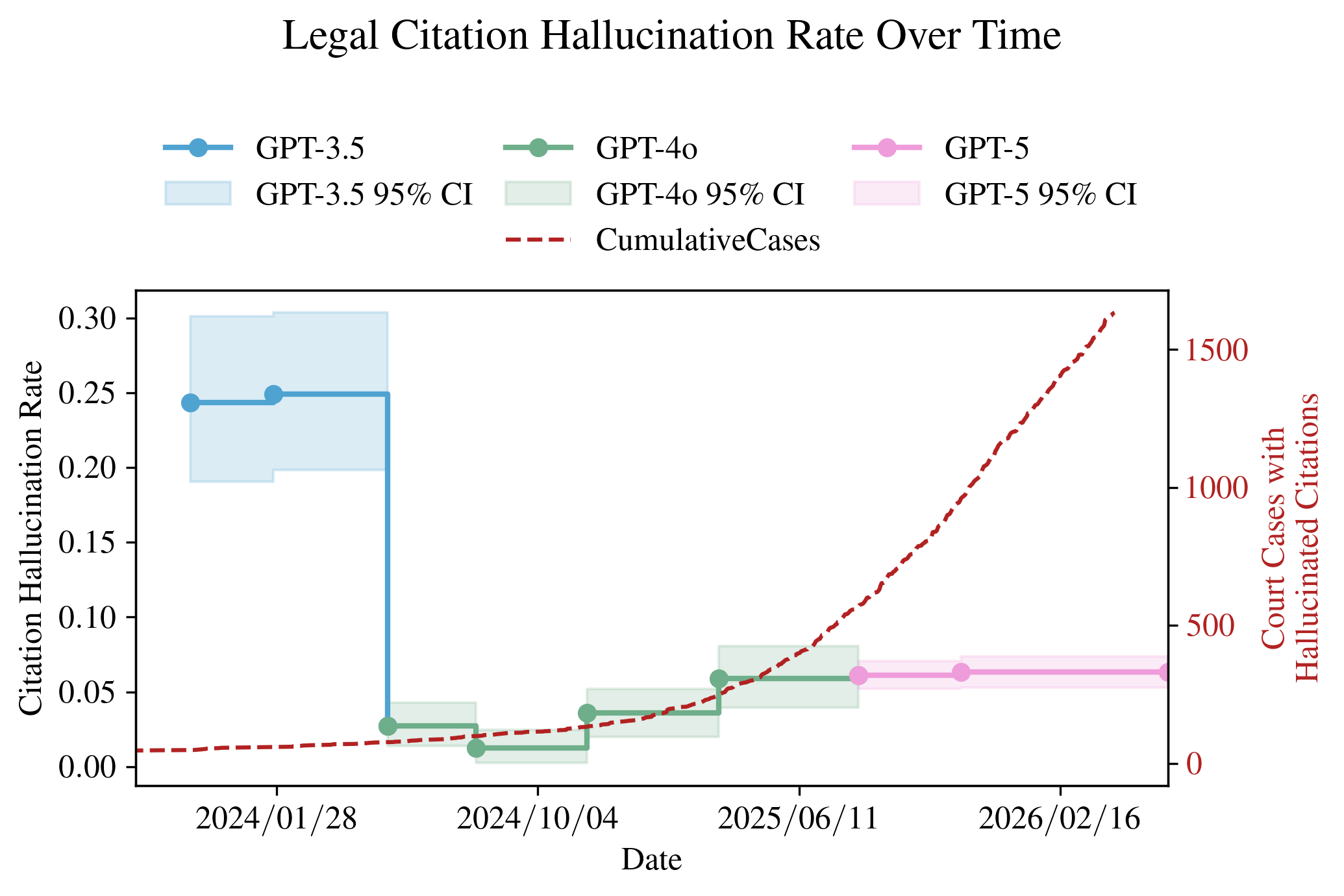
Legal hallucination rates are not consistently decreasing across GPT model generations, while hallucinated citations in court filings grow steadily. Hallucination rate is the percentage of fabricated citations in all model-generated citations.
Judges repeatedly describe the resulting burden as an "enormous waste of judicial resources," and increasingly impose sanctions because "lesser sanctions have been insufficient to deter the conduct." Mid Cent. Operating Eng’rs Health & Welfare Fund v. HoosierVac LLC, 2025 WL 574234, at *3 (S.D.Ind. Feb. 21, 2025); Powhatan County Sch. Bd. v. Skinger, 2025 WL 1559593, at *10 (E.D.Va. June 2, 2025). Courts impose these sanctions while pro se litigants — who stand to benefit most from AI's ability to improve access to justice — are least equipped to detect hallucinated citations and lack access to commercial legal databases.
Through a controlled experiment querying eight generations of ChatGPT models on 92 legal drafting prompts, we find that hallucination rates are no longer consistently decreasing across model generations. Early GPT-4o models released in mid-2024 exhibit the lowest rates at 1.23%, substantially improving over GPT-3.5's ~25%. GPT-5.1 reverses this trend at 6.57%. Newer models also generate more citations per document, drawn from a broader and less canonical set of cases that are individually harder to verify.